
Language篇(三),让AI识别垃圾邮件
前言今天是最后一个 Project 了,完整代码见 https://github.com/zong4/AILearning。
词袋模型(Bag-of-Words)之前的文章有提到词袋模型做垃圾邮件分类效果挺好的,所以先用这方法,核心代码如下。
1234567891011# 提取特征vectorizer = CountVectorizer()X_train = vectorizer.fit_transform(train_data['message'])X_test = vectorizer.transform(test_data['message'])y_train = train_data['label']y_test = test_data['label']# 训练模型model = MultinomialNB()model.fit(X_train, y_train)
构建词汇表遍历训练集中的所有邮件文本,统计出现的所有不重复的词汇,这些词汇构成了词汇表(Vocabulary)。
例如,训练集中的邮件 ...
Neural Networks篇(三),用无监督学习让AI学会画圆
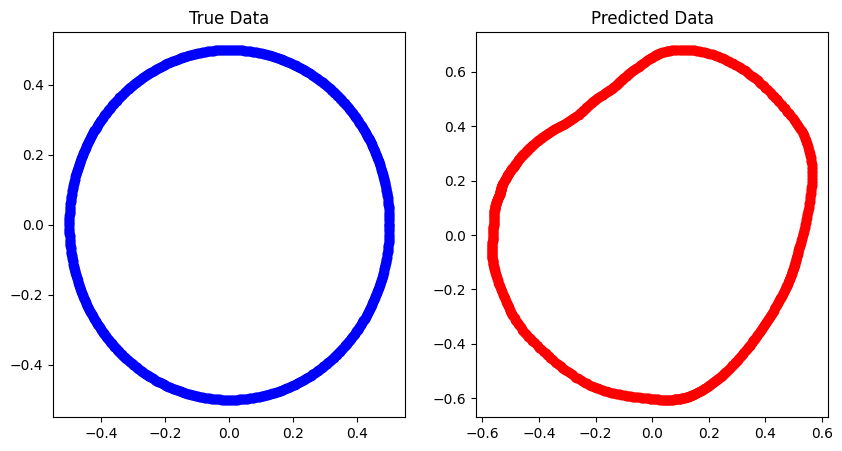
前言之前不是有说过,神经网络可以学会非线性关系,例如圆之类的,今天我们就来尝试一下,目标就是拟合出下面的圆,完整代码见 https://github.com/zong4/AILearning。
无监督学习大家先自己过一下代码。
12345678910111213141516171819202122232425262728293031323334353637# 生成圆上的数据点num_points = 1000theta = np.linspace(0, 2 * np.pi, num_points)radius1 = 1radius2 = 2x1 = radius1 * np.cos(theta)y1 = radius1 * np.sin(theta)x2 = radius2 * np.cos(theta)y2 = radius2 * np.sin(theta)data = np.column_stack((np.concatenate((x1, x2)), np.concatenate((y1, y2))))# 划分训练集和测试集train_size = int(0.8 * num_ ...
Learning篇(三),让AI推荐书籍
前言今天来写一个图书推荐引擎,完整代码见 https://github.com/zong4/AILearning。
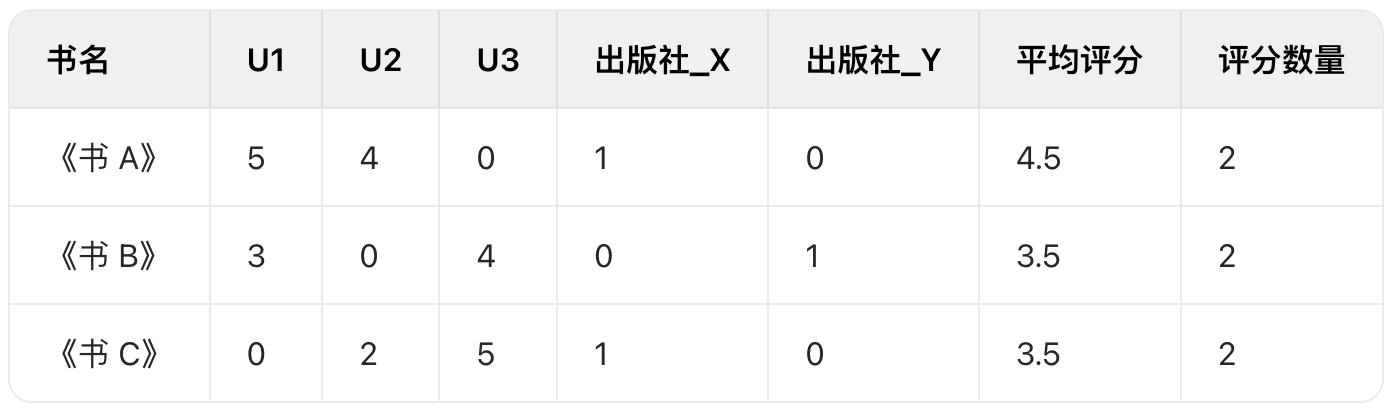
数据处理主要是有三个表,给大家看一下。
先把数据提出来,画图就不画了,数据量有点大,给我电脑干卡了。
12345678910111213141516171819202122232425262728293031books_filename = './book_recommendation/book-crossings/BX-Books.csv'ratings_filename = './book_recommendation/book-crossings/BX-Book-Ratings.csv'users_filename = './book_recommendation/book-crossings/BX-Users.csv'# import csv data into dataframesdf_books = pd.read_csv( books_filename, encoding = &q ...
Neural Networks篇(二),让AI分辨猫和狗并优化
前言今天再来做一个神经网络的分类任务,完整代码见 https://github.com/zong4/AILearning。
代码来看看比上次多了什么。
数据增强首先是考虑到图像比较少,所以通过旋转缩放来生成新的图像供 AI 训练。
123456789101112131415train_image_generator = ImageDataGenerator(rescale=1./255, rotation_range=45, width_shift_range=.15, height_shift_range=.15, horizontal_flip=True, zoom_range= ...
求证人类的本质是复读机
前言啊哈,我又来更新了,原本是想结束了来着,但是又找到了几个好玩的题,所以来更新一下,顺便把之前欠的补了,完整代码见 https://github.com/zong4/AILearning。
石头剪刀布不知道当你看到这个题目的时候想到了什么策略,总之强化学习肯定是用不了的,因为纯概率游戏是没有最优策略的,给大家看看我写的三个策略。
策略1出能赢对手上次出的那一手。
123456789# Strategy1: play the winning move of the opponent's last moveif prev_play == 'R': return 'P'elif prev_play == 'P': return 'S'elif prev_play == 'S': return 'R'else: return random.choice(['R', 'P', 'S' ...
Language篇(二),生成并观察注意力热力图
前言这是理论学习的最后一篇了,完整代码见 https://github.com/zong4/AILearning。
模型结构序列模型先来讲讲模型结构吧,如果你之前的文章有认真看,肯定会想到可以用处理序列输入和输出的模型结构。
首先将文本如下按序输入进去。
然后当输入到 [end] 符时就生成第一个输出词,然后再把输出的词按序输入,就能得到完整的输出。
这样做确实可以,唯一的缺点就是不能并行,所以当数据量大的时候,消耗的时间和算力就会成倍上升。
Transformers在 Transformers 中,我们可以做到让模型如下同时接收 Input 信息,然后处理生成 Output 信息。
但是该有的信息还是一个都不能少,所以我们首先就得补充顺序信息,如下就是通过添加位置编码来实现的。
有了信息之后我们可以通过自注意力机制分析不同词之间的关联度,从而让模型更加专注于有价值的内容,如下图就是一张学会了顺序信息的注意力热力图。
那最后为了在输出的过程中,让模型知道自己之前输出了什么,就需要将之前的未解码的输出重新输入进来并计算交叉注意力。
注意力机制原理和实现关于注意力的原理我非常推荐 ...
Language篇(一),让模型理解语法和语义
前言哈哈哈,终于来到我的专业领域了,完整代码见 https://github.com/zong4/AILearning。
语法大语言模型主要是需要解决两个问题,首先就是语法。
马尔可夫链那其中一种解决方法我们之前试过了,没错,就是当时用马尔可夫链生成福尔摩斯故事。
它的本质就是通过每组词的转移概率来分析语法,同时也可以起到预测下一组词的作用。
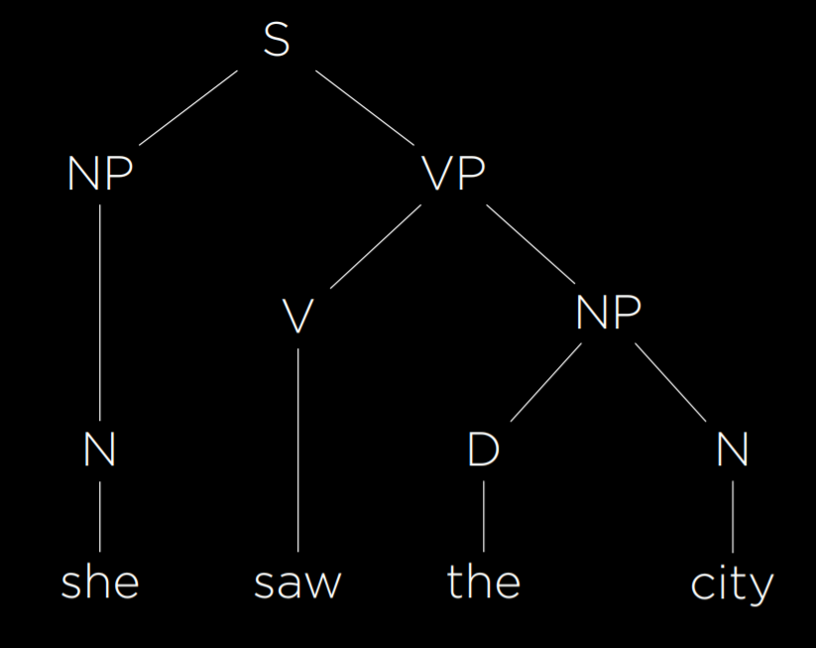
上下文无关语法除此之外我们也可以主动给 AI 提供语法,任何文本都可以用下面的语法树来表示。
不过这棵比较简单,实际情况遇到长难句会非常复杂,给大家看一句。
我输入的语法模型是这样的,不知道有没有穷尽,但是至少也分析出来了。
123456789101112131415161718192021TERMINALS = """Adj -> "country" | "dreadful" | "enigmatical" | "little" | "moist" | "red"Adv -> &q ...
Neural Networks篇(一),理解模型的结构并实战
前言上一篇说这篇要完善狼人杀的代码来着,后来感觉干脆等 Language 篇讲完再做会比较好一些。
所以今天就继续来讲神经网络,完整代码见 https://github.com/zong4/AILearning。
模型结构一维输入神经网络在我眼里其实本质是泰勒展开,即所有连续函数都可以用一长串多项式来表示。
那至于不连续函数就需要请出激活函数了,通过激活函数我们可以做到截断一些函数再组合,从而实现特殊的图案。
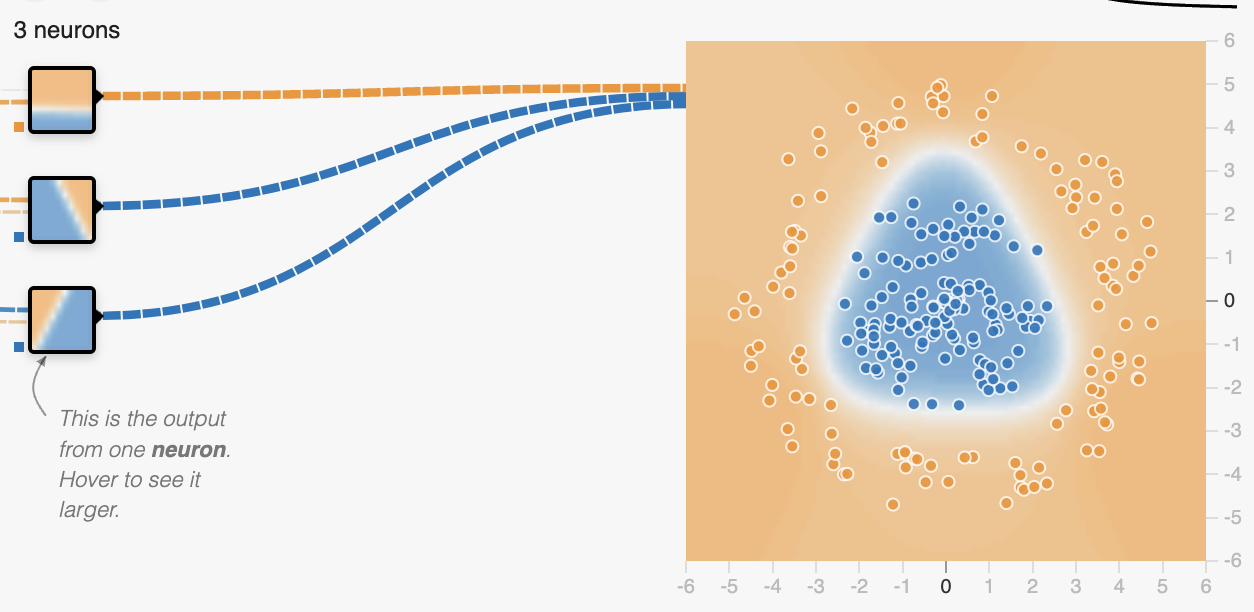
给大家看个好玩的,如下图,我们现在要搭建一个模型来完成这个分类任务。
那目前我们只有输入层和输出层,也就是机器学习,很明显它没有办法把中间的蓝色包裹起来,只能划出一条斜线。
现在我们试着加入一层隐藏层,也就是中间层,可以看到当中间层有三个节点时,它就已经能完成分类任务了。
这三个节点的输出分别是三条线,如下。
这就是我上面所说的通过激活函数配合多项式来实现一些特殊图案,至此我们就理解了为什么 AI 能处理所有的一位数据,接下来我们来看看多维数据。
多维输入多维数据中首当其冲的就是图像了,那我们该如何让 AI 处理这二维数据呢,或者说我们该如何讲二维数据转换成一维数据呢? ...
Learning篇(二),用强化学习玩尼姆(取物)游戏并泛化至任意情况
前言很快啊,今天的第二篇,完整代码见 https://github.com/zong4/AILearning。
Reinforcement Learning终于来到我最喜欢的强化学习了。
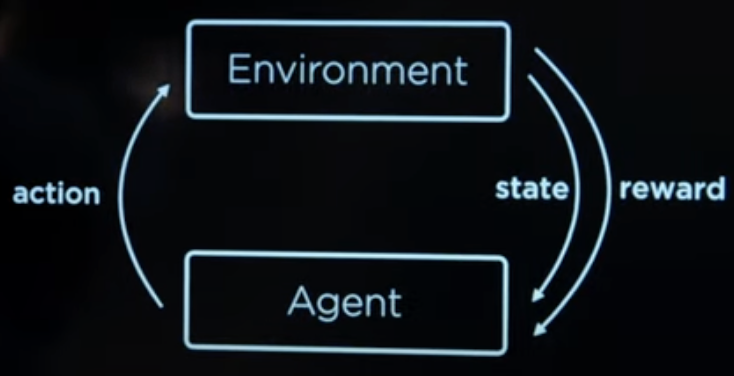
强化学习中各要素的关系如图所示。
环境会告诉代理目前的状态,由此可以推出代理可以作出的行动。
代理根据自己的判断选择行动后,环境会给出相应的惩罚或者奖励。
不断循环上面两步直到代理成功或者失败。
继续训练,不断的开始下一局游戏
OK,那接下来我们就来看个例子吧。
尼姆(取物)游戏给大家看一眼应该大家就知道怎么玩了,我这里的话是谁最后取完谁输。
小潮院长他们最新一期羊村也玩了。
Agent这里用的学习算法是 Q-learning,公式如下。
$$Q(s, a) <- Q(s, a) + alpha * (new_value_estimate - old_value_estimate)$$
其中 alpha 是学习率,new_value_estimate = reward(现阶段的奖励)+ best_future_reward(未来最大的奖励)。
具体实现主要是下面的 updat ...
Learning篇(一),用机器学习做分类任务
前言不多说了,今天争取写两篇,完整代码见 https://github.com/zong4/AILearning。
Supervised Learning先来讲讲监督学习。
监督学习最大的特点就是有数据标签,会有人告诉 AI 那个东西是什么,这样的话准确性肯定会高一些。
最常见的应用的话就是 Classification(分类),我们也来试一下,基本就是一通百通。
预测用户是否购买在这个例子中我们将根据给出的数据来预测用户在网上购物时是否会购买商品,从而判断是否给它推广告。
主函数先来看看主函数。
首先需要加载数据,并分成训练集和预测集。
然后的话就开始训练模型。
再让模型去预测集上跑一遍输出预测结果。
最后来算一算模型的 Sensitivity(真阳率)和 Specificity(真阴率)。
123456789101112131415161718def main(): # Load data from spreadsheet and split into train and test sets evidence, labels = load_data("./ ...