
Search篇(一),让AI走迷宫
前言完整代码见 https://github.com/zong4/AILearning。
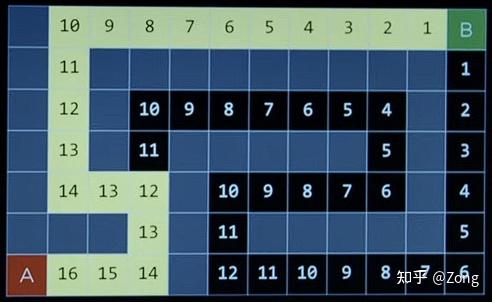
定义所谓 Search 就是寻找最优解。
生活中的话像导航,或者之前比较火的 AlphaGo 下围棋都算,我们就从比较有代表的迷宫开始。
Maze顺带一提,之前做雅思,好像 amaze 就是从 maze 延申出来的。
每一个 Maze,或者说每一个 Search 问题都能被分成以下几个部分。
Agent或者说 Player,如果是导航,那 Agent 就是你自己,如果是博弈游戏,那就是参与游戏的每个人。
Initial State同样的,如果是导航那就是你的起点,如果是围棋,那就是空棋盘。
Actions被规则允许的所有 Action。
Transition Model123def Result(State, Action): ... retun state
State Space没什么好说的,状态转移图。
可以被简化成有向图。
Goal Test没什么好说的,不然连解出来了都不知道。
Path Cost Function不同问题中的 Path Cost 是不一样的,可能是时 ...
基础篇
前言好久没更新了,之后尽量日更,最近在 gap,下半年去北欧读研,最近就随便学点感兴趣的东西。
我会尽量研究的透彻点,到研一的 level 吧(hope),代码基本都会附,但不会给全,不然你们都不思考。
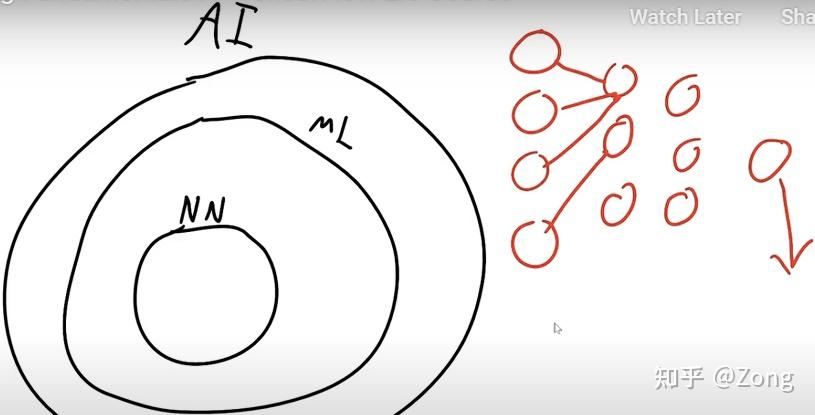
定义Artificial Intelligence模拟人类的行为来解决问题。
Machine Learning和传统算法的区别在于目的是发现规律(Rules),和不是获取结果。
Deep Learning / Neural Networks相比于 ML,多了很多中间层。
NN 不是模拟人脑。
路线分成 Search,Knowledge,Uncertainty,Optimization,Learning,Neural Networks 和 Language 七个 Part 来理解 AI。
参考资料Harvard CS50’s Artificial Intelligence with Python – Full University Course
Machine Learning with Python Certification | freeCodeCamp.org
以及 ...

基于色彩理论像素化任意图片
代码画像素画观察先看了会大佬的像素作品(32 * 32),感觉像素画主要就是把关键特征保留下来。
动手看了个 b 站的视频,感觉还不错,决定自己也动手临摹一下。
找了张图。
虽然很不甘心,但是我的美术功底好像确实也就到此为止了,实在是太丑了!
图片像素化既然我自己画不行,那就只能让电脑来画了。
纯算法个人还是喜欢用纯算法的方式解决问题(可解释性强)。
改进图像缩放从本质上来说,图像缩放就是去除冗余像素的过程,但是却无法生成一幅赏心悦目的像素画。
其根本原因在于没有突出重要部位的颜色(色差不明显),而是一味的使用均值平滑缩放。
因此,可以先按照缩放比例,将原图像分块,再剔除块内的偏离值,最后取平均值映射到新图像的相应位置。
12345678910111213141516# Every channelfor page in range(0, channel): mean = np.mean(block[:, :, page]) std = np.std(block[:, :, page]) # 剔除 2σ 异常值 numMaxEdge = mean + 1 * ...

Blender基础全流程
前言总所周知,美术是独立游戏很重要的一块,可以不好,但是不能没有,所以就开始学Blender啦。
然后油管上有个视频展示了一下他学了一周Blender的成果,看着还不错 https://www.youtube.com/watch?v=OrmKzaeoL2c,所以我也打算先努力学习一周,至少得做到可以自己制作想要的场景。
Day1 & Day2找了油管比较火的教程来看 https://www.youtube.com/watch?v=B0J27sf9N1Y,先做个甜甜圈,熟悉一下Blender。
Part1Follow the part1, I make some caps/hats for the monkey.
Part2 & Part3: ModellingBefore it, I try to place three simple torus, it is pretty interesting.
However, we should make our models a little strange, not prefect, or they are ...

Where is my life? 我的人生在哪里
前言他,23岁,一事无成,但是找到了自己的路。
很久没有写文章了,前段时间一直很迷茫,我总是想为我所做的事情赋予一些意义,说服我自己去完成它,真让我感觉非常痛苦。
明知它是没有意义的,但我却要不停的相信它是有意义的,这甚至让我有点精神分裂。
直到昨天,我洗澡的时候在想,为什么我不干脆直接承认所有的一切都是无意义的呢?
将我的人生比作游戏,不断地发起挑战。
也许这样的人生态度可以支撑我走的更远。
这不禁让我想起了《西西弗斯神话》,加缪说我们应该想象西西弗斯是快乐的,在那一刻我终于理解了他,西西弗斯应该是快乐的,他也许就在不断地挑战着他自己。
更快,更高,更持久。
从今年2月到现在,9个月的时光,我一直在思考这个问题,很庆幸我现在终于有了自己的答案,终于可以更加坦然的面对自己。
为了纪念,于第二天(2024/11/15)写下这篇文章,同时也会在今年将其做成视频,希望能给有相同困境的朋友们一些启发。
正文What is the meaning of life? Everyone has their own answers, maybe eating everything, ...